The biggest limitation of today’s Large Language models (LLMs)—or just ChatGPT for many people who aren’t in the AI space—is the tight coupling between the language, knowledge and context. I call today’s kind of statistical approximation ‘lossy’ because its representation cannot be converted back to the original meaning at all times.
Now I’m biased because I have solved how brains work sufficiently to vastly improve AI with an implementation that will revolutionize how our devices work. With sufficient funding we can demonstrate our differences while progressing a valuable roadmap for society. I laid this out in my book ‘How to Solve AI with Our Brain’ including my 5 year vision and how this will be achieved, in Chapters 18-20.

Knowledge versus language: what’s the difference?
The problem with today’s “AI” is that it models language as a sequence of words (tokens). While it is true that language is normally produced as a sequence of words, the sequences are flexible across each language and also different between the world’s languages. Full flexibility comes from the meanings of words.
In this sentence: “Can you call my wife, I mean Sue, no Samantha, um, text her?” it has nothing to do with calling. It is a command about texting Samantha even though the syntax with the words used is statistically similar to ‘calling my wife.’ Sue is just an error in the text.
Spoken language has lots of ‘errors.’
In today’s AI, transformers are used to identify the most statistical match across many dimensions. This is effective for some problems, but not others. The main use-case is human ‘conversation,’ in which the resolution of context is critical but out-of-reach of the LLM. The most statistically valid context from Background knowledge (General Common Ground—GCG) is rarely the best choice in the current context (Immediate Common Ground—ICG).
Language depends on ICG extensively to provide concise communications, exploiting ‘common sense.’ A system without ICG is unlikely to pivot to one that has it, without fundamental disruption and high cost.
Therefore, the most likely breakthrough is a system not based on statistics but based on ‘context’.
What does this all mean?
Knowledge—who said what to whom, when, where and why—is different to what is said now (to who, where, when and why). Language deals with this immediate context (ICG) to resolve the meaning of each sentence, validating with questions if needed.
In the following example, the meaning of the language: “The man bought a car from the dealer for one dollar” involves a well specified transfer of goods.
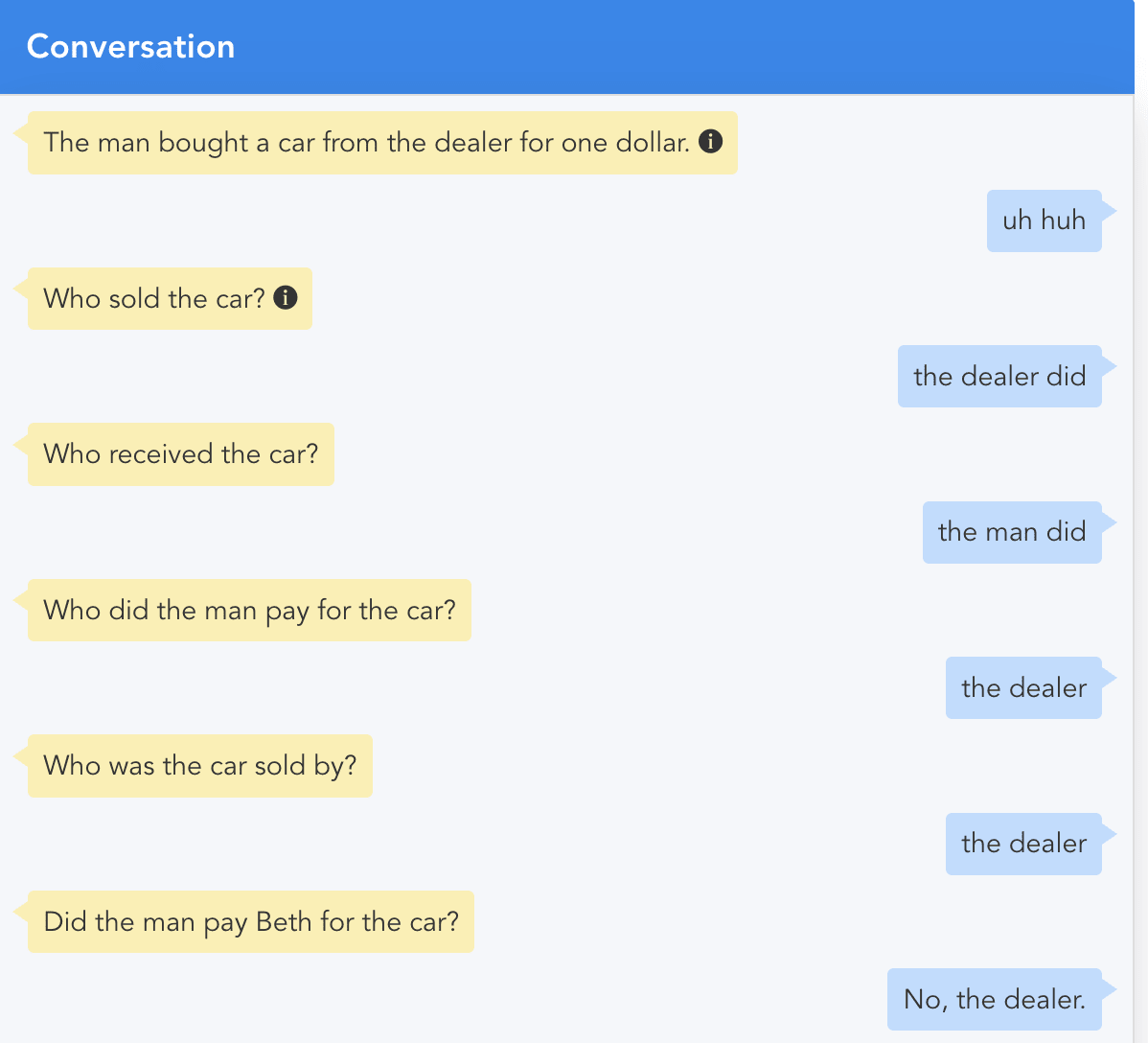
Notice that the context was entered into the conversation on the first line. There is no other background knowledge involved in this example—it is all ICG (current context).
The meaning of the other words in the questions like ‘pay for,’ ‘receive,’ and ‘sold’ weren’t in the initial context, but effortlessly are resolved by the meanings of the initial language (a command) and the meaning of the question.
In other words, without any training (compare to the $100m+ for an LLM training run) the system can use the language to perform valuable work as is needed in essential device interactions.
Meaning from Language
The meaning in language is powerful. We use it to learn new topics. That is the purpose of education. At universities, for example, students don’t learn the language in say, chemistry, mathematics and engineering, but instead learn subjects by using their existing language.

In the battle against wasteful uses of energy that for today’s popular AI has resulted in a proposal for $500 billion USD to create new data centers and their corresponding nuclear and coal-fired power plants, the split between knowledge (scraping the world’s Internet data and ‘ignoring’ copyright) and language (setting up an appropriate dictionary) contrasts sharply.
The system I am demonstrating here runs on a laptop easily.
The base system doesn’t include a populated knowledge representation, but language itself is so powerful as to provide useful services without external knowledge (GCG).
Conclusion and Next Steps
In my author talks, I often point out that emeritus professor of computer science, Thomas Dietterich from Oregon State University highlights the need to split language from knowledge to enable the next generation of AI to eliminate hallucinations caused by that statistical coupling.
In my author talk here (click) you can see how I present that at around the 29:30 mark.
There are strong reasons for moving away from the current ChatGPT-style of AI that cannot be trusted due to hallucinations and its high cost of operation in favor of the next generation of AI as demonstrated today. Progress requires not only a wish to achieve a goal (hopium), but also the capability to get there.
Moving back to a model that is setup as normal software is an obvious next step on the path to human-level AI that starts at a low price with low energy consumption.
Do you want to read more?
If you want to read about the application of brain science to the problems of AI, you can read my latest book, “How to Solve AI with Our Brain: The Final Frontier in Science” to explain the facets of brain science we can apply and why the best analogy today is the brain as a pattern-matcher. The book link is here on Amazon in the US.
In the cover design below, you can see the human brain incorporating its senses, such as the eyes. The brain’s use is being applied to a human-like robot who is being improved with brain science towards full human emulation in looks and capability.



