

背景
1930年代、アメリカでの行動主義への注目は、言語学の世界を記号の科学(記号論)から、おそらく紀元前7世紀に生きた歴史上の偉大な科学者の一人であるPāṇiniに沿ったものに変えました。レナード・ブルームフィールドによるパーニニの言語モデルの使用は、1957年に出版された影響力のあるチョムスキーのモノグラフSyntactic Structuresのように、言語学が意味を除外することにつながりました。
私が提案する記号論への回帰は、ロバート・D・ヴァン・ヴァリン・ジュニアの非常に影響力のある研究の副作用です。彼の過去40年以上にわたる役割と参照文法(RRG)の開発は、言語の単語やフレーズ(形態構文)と文脈におけるそれらの意味(文脈的意味)を明確に区別しています。RRGは、世界の多様な言語を、形態構文から意味へ、そして単一のアルゴリズムを使用して戻る階層化されたモデルとして見ています。
AIが人間を模倣するためには、今日の能力よりもはるかに多くの能力が必要です。例えば、基本的な動物の脳の能力である単純な階層モデルや、意味が必要です!
意味の使用は次世代AIを開始します
1956年、ジョン・マッカーシーやマービン・ミンスキーを含む先見の明のある人々は、人間が行うことをどのように模倣するかに焦点を当て始めました。彼らは彼らの新しい分野を「人工知能」と呼びました。今日、私たちはそれをAIと呼んでいます。しかし、人間が知性と呼ぶものを模倣する機械の探求は、期待外れの結果で続いています。
ジェッツン家のロボットメイドで家政婦のロージーの兆候はありませんでした。また、2001年宇宙の旅からのハルの兆候もありませんでした。ハルは少し無作法だったので、おそらくそれはOKです。
何が間違っていたのでしょうか?
時間はすぐに過ぎますが、科学は一度に一つの葬式を進めます。それはマックス・プランクによって作られた概念であり、彼は知っているでしょう!
私たちは真のAIを作成しますが、まず古いアイデアを取り除き、科学的方法を取り入れる必要があります。
今日の記事では、次世代AIの私の青写真について考察します。それは、1956年のそれらの先見の明のある人々が応援するであろうものであり、コンピュータに関する彼らの専門知識と仮定の一部が除外されることを意味するにもかかわらずです。
コンピューティングは間違ったモデルです
今日のAIの制限について考えるとき、デジタルコンピュータの弱点との類似点を見ないわけにはいきません。コンピュータのデータは、多くの場合、紙の上にエミュレートされます。データ要素のボックスをいくつか描き、ボックスに数字または文字を書き込みます。数字または文字は、今日のコンピュータで実行される多くの形式のバイナリエンコーディングの1つです。次に、ボックスを操作したい場合は、情報理論を使用して、コンテンツを他の場所に正確にコピーします。
脳にとって、これは異質な概念です。脳は比較的速度の遅い機械であり、その要素であるニューロンは数ミリ秒で活性化します。それは100ステップルールにつながります。これは、複雑なイベントに対する私たちの反応時間がニューロンの100回の連続した活性化のみを可能にするという不可解な提案です。
視覚、聴覚、その他の感覚要素を持つ複雑なシーンを認識し、何らかの推論またはプログラムを使用して、アクションを実行することを決定し、多数の筋肉の活性化で必要な動きを開始する必要があるプログラムを作成することを想像してみてください。このプログラムは100の連続したステップを超えてはなりません!
並列処理に対する現在の熱狂は、グラフィカルプロセッシングユニット(GPU)を使用した代替アプローチですが、コンピュータは少なくとも私たちの脳よりも数百万倍速い速度で開始し、そのモデルの結果は依然として人間の能力に及ばない。
並列処理は100ステップルールを受け入れますが、脳はどのようにそれを実装するのでしょうか?
パトム理論は、脳が行うことを理解するために、2000年代初頭に私が推進した脳機能のモデルです。
コンピュータとは異なり、脳は多数の感覚入力から始まります。目では、数百万の信号が受信した光と色を示します。耳では、信号は受信した音の周波数範囲と、バランスのための重力に対する頭の位置を示します。私たちは世界と私たちの位置を理解するのに役立つ多くのセンサーを持っています!
情報を保持して送信するためにデータを保存するのではなく、脳は最初に一致した場所にのみ情報を保存し、階層システムを使用して、パターンが双方向に結合するように見えます。理論的には、直接分析によって視覚入力から部屋いっぱいの人々を認識できますが、それは多くの処理です!私たちの脳は部屋の画像で人々を見つけるためにどこから始めますか?
100ステップルールを満たすためのパトム理論の原則は、センサーが接続するエッジでパターンを照合し、それらを一意に結合することです。一意の形式は検索の必要性を排除します。なぜなら、何かのコピーが1つだけ保存されるからです。大きなパターンは、発見されたときに分解された組み合わせに洗練され、元のパターンに結合するさらに小さなパターンのセットをサポートします。
パターンが領域間で構成されると、双方向リンクがリンクされたセットの概念を組み立てます。完全なパターンは、感覚に保存された以前のパターンのコレクションとして組み立てられます – 逆リンクを使用します。リンクされたセットまたは単にリンクセットは、原子パターンを物理的に接続します。したがって、脳損傷の影響は、接続リンク(白質)の喪失とパターンストレージ(灰白質)の間で微妙に異なります。領域は、パトム理論の中心的な要素であり、個々のニューロンではなく、通常、冗長性を提供するリンクセットに多くの領域があります。
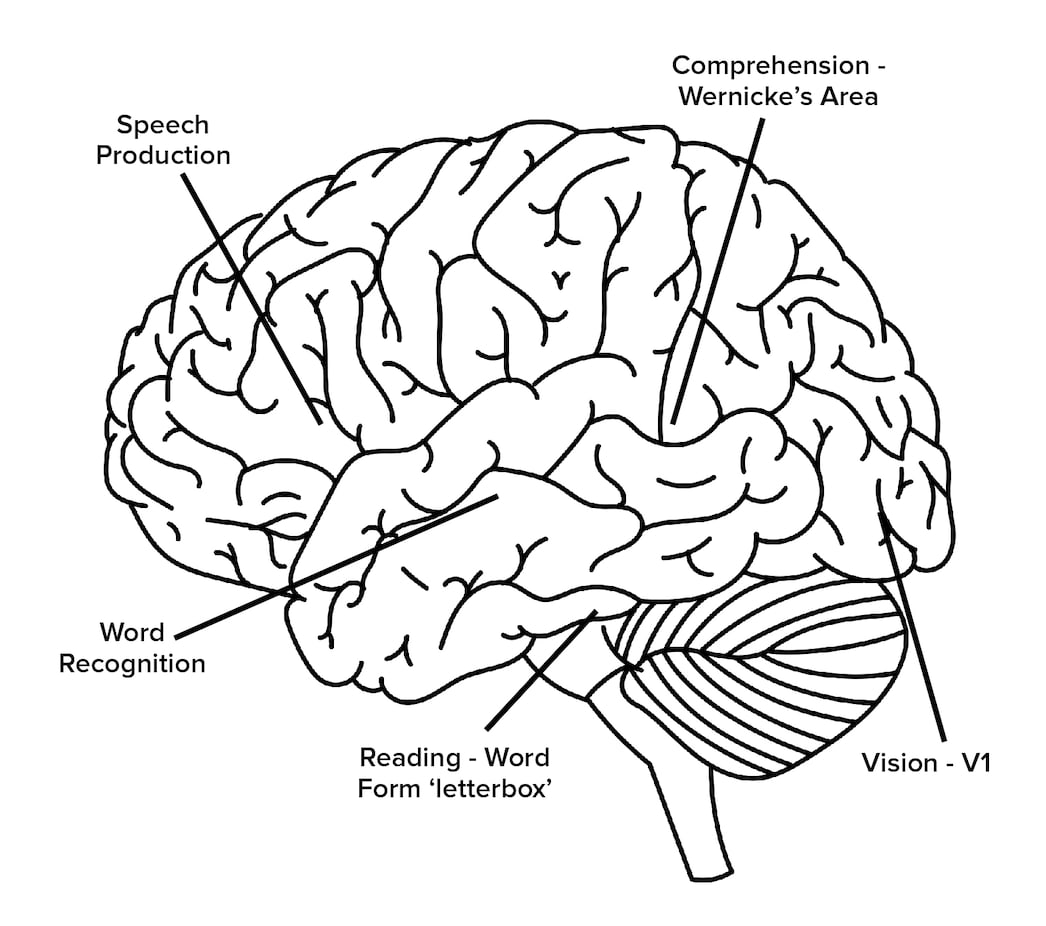
パターンはシーケンスとセットです。運動制御は、動物のスムーズな動きを容易にするために、多数の筋肉が活性化され、同時に非活性化されるシーケンスとして、このモデルを示しています。
これらのパターンは、脳領域の解剖学に見られるように、双方向です。これは、初期パターンが学習され、エッジパターンが結合して多感覚パターンを形成するため、ボトムアップで保存されることを意味します。双方向の性質により、これらのパターンはトップダウンでもあり、パターンの断片が何が見えるかと同様に予想されるものと一致することを可能にします。例えば、ヒョウの尾は、認識された場合、ヒョウの完全なパターンと一致し、視覚システムに貴重な生存上の利点をもたらします。
このモデルの脳領域はすべて同様です。感覚からのパターンは領域で認識されます。同様に、このモデルは筋肉の制御にも同様に機能すると提案されています。なぜなら、動きには、バランス、固有受容、および有効性をサポートするその他の機能を含む感覚入力とともに、シーケンスで多数の筋肉の協調が必要だからです。
要約すると、脳は理論的にはパトム理論で複雑なパターンを保存できますが、エンコーディングに基づく既存の計算モデルを作成するという概念は効果的ではありませんでした。さらに悪いことに、エンコーディングは脳機能と一致していないようです。脳には明らかな情報のエンコーディングはありません。パトム理論は、もっともらしい代替手段を提供します。
意味とは何ですか?
脳では、意味はパターンとの可能な、既知の組み合わせのセットの認識です。進化の初期の動物は、捕食者からの逃避と獲物の追跡を選択するために、状況の意味を使用します。そのような行動は、感覚と運動制御の複雑な組み合わせです。
人間では、記号の科学である記号論は、初期の動物におけるこの基本的な意味の使用を改善することを可能にします。
知識対意味
意味は、説明されているように脳の構成要素ですが、知識は意味との区別で最もよく定義されます。脳全体での意味の保存は、文脈におけるすべての同時要素を含みますが、その構成要素は常に制約されているわけではありません。
事実の概念は、これをさらに拡張します。
認知的不協和は、私たちが一度に複数の矛盾したことを認識することを妨げます。錯視はこれを示しています。しかし、現実の世界では、複数の矛盾したアイデアを保持できます。コンピュータ科学者は、応答を述べられた事実に制限しようとしますが、それが私たちの脳の働き方ではありません。私たちは、文脈において、一部の人々がXを信じており、他の人々がXでないと信じていることを知っています。
事実はありません
脳では、矛盾したアイデアを一度に保持することはできず、それらの間での選択を余儀なくされます。しかし同様に、事実の概念は脳と一致していません。なぜなら、脳はサブセットだけでなく、完全なパターンのレベルで動作するからです。
例えば、ウォールストリートジャーナルのエピソードの1つの要素は、「トランプは天才だ」という意味を含むことができます。ニューヨークタイムズの別の要素は、「トランプは馬鹿だ」という矛盾した意味を含むことができます。
個人的な意見はこれらの項目の1つ、両方、またはどちらでもない可能性があります。なぜなら、各要素は単にイベントの意味であるか、おそらく、より効果的に命名された知識であるからです。
コンピュータサイエンスの知識を調整する
役割と参照文法のような言語学は、文の意味をモデル化します。人間の言語のモデルとして、RRGモデルは人間が思い出すことができるのと同じくらいロスレスにすることができます。会話でこれらの文を操作するためには、意味の表現を単一のモデルに調整するのが最善です。
コンピュータサイエンスはプログラマーが任意のモデルを定義することを可能にしますが、今日の知識グラフは、言語学へのより緊密な調整によって改善することができます。それは認知科学の単純な応用ですが、認知科学のどの部分を採用するかを選択する必要があります。
RRGは、意味のある世界 – セマンティクス – を、物を関連付ける述語と、物である指示対象と区別します。他のコンポーネントもありますが、意味の構成要素は述語と指示対象として正確にモデル化できます。
知識グラフ
RRGと今日の知識グラフの違いは何ですか?
まず、言語の単語形式とその意味には違いがあります。第二に、意味は状況に応じて、多くの異なる単語形式で記述できます。第三に、一部の単語形式のシーケンスは、構成された単語自体に独立した意味を提供できます。最後に、知識グラフは、比較を実行するプログラムを使用せずに比較を実行できるように、述語レイヤーを調整する必要があります。比較は自動である必要があります。
セマンティック述語と指示対象(構文的用語ではない)
意味図(知識グラフ)で意味を表すために単語と構文的記述を使用する代わりに、セマンティック要素を使用する方が良いです。
次の図(図1)は、英語のような特定の言語で表される意味の制限を示しています。(注:以下の図はWikipediaのエンティティ関係モデルからのものです)。
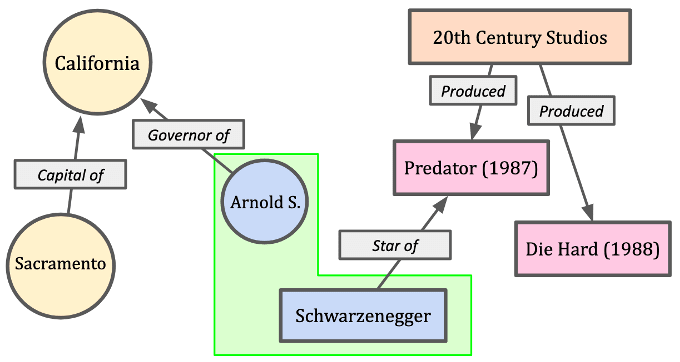
図2は、選択された単語に対する人間の理解に依存しているため、うまく一般化できません。「シュワルツェネッガー知事」はアーニーの有効な名前ですか?もしそうなら、それは除外されています!アーニーを英語だけで識別する方法はたくさんあるため、彼の指示対象は、例えば、r:arnieによって一意に識別される必要があります。これは、英語では、可能な識別子の範囲に、フレーズパターンによって直接的または抽象的にリンクされます(例:「シュワルツェネッガー知事」、「アーノルド・シュワルツェネッガー」、「アーノルドS.シュワルツェネッガー」、「シュワルツェネッガー氏」、「アーノルド・シュワルツェネッガー氏」、「アーノルド・シュワルツェネッガー知事」、「シュワルツェネッガー元知事」など)。次に、r:arnieは、それを識別するすべての言語固有の用語を表します(「1987年の映画「プレデター」のスター」を含む)。
カリフォルニアは米国地図にレイアウトされた地域ですか?もしそうなら、土地は知事を持っていません。代わりに、米国の州は人々に統治される団体であり、その団体は知事を持っています。土地にはサクラメントのような都市がありますか?それは地図上の地域ではないですか?重要なのは、人間がこれらのラベル(記号)の意味について多くのことを知っており、それが知識表現から除外されるべきではないということです。知識を人間の能力と調整する – それは英語の単語ではなく、意味を使用して知識を表すことから始まるプロセスです。
今日の私の言語ベースのAIシステムでは、指示対象を表すためにr:sacramentoのようなラベルを使用し、述語を表すためにp:produceを使用します。言語を独立させるために、そのような辞書の単語センスは、r:123456やp:654321のように、言語に依存しない方法でより適切に識別されます。もちろん、これらのセマンティック項目は、特定の言語でそれらを識別するマッピングで最もよく表現されます。

さらに重要なのは、知識グラフで一般的に使用される命名法です。図3では、構文的用語の使用は、意味の関係(セマンティック述語)が名詞と動詞(および形容詞と副詞の場合もあります)の両方になり得るため、エンティティと関係を識別し、モデルの根本的なあいまいさをもたらします。時間、空間、および理由(通常、構文的名詞、命題、および副詞)のような属性も述語ですが、明確に説明されていません。


図5では、RRGの述語(動詞)は0、1、2以上の引数を持つことができます。このアプローチは、属性、場所、時間など、より自然に述語の範囲を扱います。これを使用して、はるかに簡単に一般化し、文の意味の比較を自動化します。
名詞も重要です
上記のERのガイディングルールの欠けている部分は、述語の名詞化された形式です。派生形式(例:破壊)やアクション名詞(例:…の破壊)、動詞のように動作するが名詞のように使用されるもの(例:ヴァンダル族が都市を破壊するため…)や動名詞形式(例:ヴァンダル族による都市の破壊は…)のような構文的名詞である述語があります。
***パート1の終わり***
***パート2では、ストーリーは言語学で識別された人間のセマンティックモデルと一致するように知識グラフを調整し続けます。語彙をどのように学習するのでしょうか?RRGにはどのような種類のフレーズがありますか?作業パーサーはどのように効率的にテキストから意味に変換し、文の埋め込まれた意味に対処するのでしょうか?明日公開予定。***
もっと関与したいですか?
ゲーム化された語学学習システムを可能にする今後のプロジェクトに関与したい場合は、進捗状況を追跡するためのサイトはこちら(クリック)です。そのサイトの連絡先リストにメールアドレスを追加して、情報を入手することができます。
もっと読みたいですか?
脳科学のAIの問題への応用について読みたい場合は、私の最新の本「脳でAIを解決する方法:科学の最後のフロンティア」を読んで、私たちが適用できる脳科学の側面と、今日の最良のアナロジーがパターンマッチャーとしての脳である理由を説明してください。本のリンクはこちら、米国のAmazon(および他の場所)にあります。
以下のカバーデザインでは、目のような感覚を取り入れている人間の脳を見ることができます。脳の使用は、脳科学でルックスと能力の完全な人間のエミュレーションに向けて改善されている人間のようなロボットに適用されています。